Every Webmaster knows that a considerable part of the traffic comes from Search Engine Robots which in most cases benefits the site. All mainstream search engine robots (Bots as they are called in our circles) obey the directives found in the robots.txt protocol and exhibit normal crawling behavior. But there are bad bots which not only consume considerable bandwidth without offering any tangible benefits to the Webmaster, but also siphon off content to be used elsewhere, or even cause spurts in resource requests resulting in slowing down the server.
It is always an onerous task to keep these malevolent bots in check. As a system administrator for dozens of production servers over the last 15 years, I can tell you one thing – that keeping the bad people, and their bad bots away from their targets, takes up a sizable time.
There are many ways to handle this and every Webmaster I have come across, handles the situation in her/his own way. As long as you stay ahead of them, whatever the technique/method you use is probably working and at the end of the day – that is all that matters.
We often come across queries in online communities about the best technique to manage this overwhelming task. This How-to ‘on identifying the bad bots’ is intended to help the average webmaster to get a handle.
Bad bots generally disobey the directives in robots.txt or they read them to look for prohibited directories to crawl. Some times it need not be a fully grown robot that sucks up your bandwidth. It can be a home-grown ‘grabber’ that can be unleashed – using utilities like wget or curl.
Not all bots are bad. Other than the search engines, some robots are operated by other legitimate agencies to determine the best matching campaign for a page’s content for a potential advertiser or to look for linking information or to take a snapshot for archiving purposes. We have trawled through our server log files to compile a list of robots you are likely to find in your server log here: Bot List .
Tip:You can scroll through the list at your leisure or if you are impatient like me, start typing the name of the robot in the form and it will show you the probable match.
The list contains bots with identifiable information given in their User-Agent field. When you browse through the list, you will also find that many major search engines switch User-Agent strings as per their need.
For example Google may use any of the following:
Mozilla/5.0 Googlebot/2.1; Mediapartners-Google Googlebot-Image/1.0 DoCoMo/2.0 N905i(c100;TB;W24H16) Googlebot-Mobile/2.1;
or anything that suits its fancy.
This list of bots shows bots – most of which obey the robots txt protocol. In case you block them in your robots.txt and still they show up, don’t break into a sweat. It may have cached your robots.txt and it may have an older directive. Wait for 24 hours before you decide to take any punitive step.
Identifying the Bad Bots
Start with the server log files. Download the recent or the last month’s server log file for analysis from the server. Or if you want to take a look at the snapshot of the last 300 entries from the server log files shown from a cPanel as here: Latest Visitors → your domain name – > View → Scroll down and hit the ‘Click Here for the legacy version’ . It will show you a list of all the last 300 requests.
The following is a part of such snapshot. It shows you the bots from Yahoo and Bing crawling some pages from TargetWoman site. As you can see, the regular search engines will request a copy of the robots.txt before they crawl the site. They will cache the robots.txt file for a time so that they don’t need to keep requesting this file all over again.
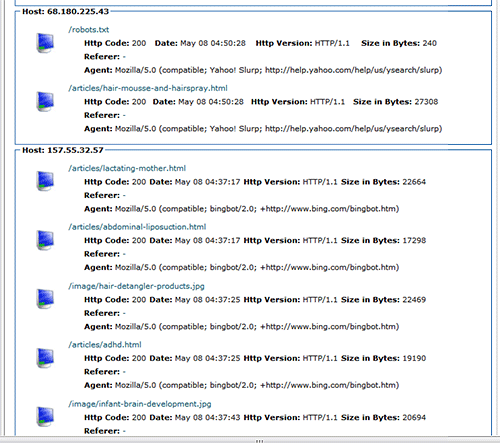
One of the techniques to isolate the bad bot is to set up a ‘spider trap’ where you add a hidden link in the body of your main page. It is hidden from the human visitors but can be reached by any crawler as it parses the main page. This link is blocked in the Robots.txt and normal bots will avoid this link. But the bad bots will still go ahead and crawl this page.
To give you an example:
Block bots.cgi in the robots.txt like so:
User-agent:* Disallow: /cgi-bin/bots.cgi
The following is a sample Perl Code to demonstrate how this simple script can write a log file of all the bad bots – with a few details:
#!/usr/bin/perl
# Script to add Bad Robots who disobeyed the robots.txt to a list
# Script by TargetWoman.com
# Date formatting
($sec,$min,$hour,$mday,$mon,$year,$wday)=(localtime(time))[0,1,2,3,4,5,6];
$time= sprintf("%02d:%02d:%02d",$hour,$min,$sec);
$year +=1900;
$mon +=1;
# print date in the way we want 1st March,2014 etc
if ($mon == 1) {$mono="January";}
elsif ($mon == 2) { $mono="February";}
elsif ($mon == 3) {$mono="March";}
elsif ($mon == 4) {$mono="April";}
elsif ($mon == 5) {$mono="May";}
elsif ($mon == 6) {$mono="June";}
elsif ($mon == 7) {$mono="July";}
elsif ($mon == 8 ) {$mono="August";}
elsif ($mon == 9) {$mono="September";}
elsif ($mon == 10) {$mono="October";}
elsif ($mon == 11) {$mono="November";}
elsif ($mon == 12) {$mono="December";}
if ($mday == 1) {$dayoo="1st";}
elsif ($mday ==2) { $dayoo="2nd";}
elsif ($mday ==3) { $dayoo="3rd";}
else { $dayoo="$mday th";}
if ($wday ==1) {$weekday="Mon";}
elsif ($wday ==2) {$weekday="Tue";}
elsif ($wday ==3) {$weekday="Wed";}
elsif ($wday ==4) {$weekday="Thu";}
elsif ($wday ==5) {$weekday="Fri";}
elsif ($wday ==6) {$weekday="Sat";}
elsif ($wday ==7) {$weekday="Sun";}
$timo="$hour:$min: $weekday, $dayoo,$mono,$year";
# Collecting details about the pesky bots
my $ua= $ENV{'HTTP_USER_AGENT'};
my $ip= $ENV{'REMOTE_ADDR'};
my $ref= $ENV{'HTTP_REFERER'};
# Time for Action
my $file="temp/bad-bots";
open( LOG, ">>$file" );
print LOG "$ua\|$ip\|$ref\|$timo\n";
close LOG;
print "status:200 OK\n";
print "Content-type:text/html \n\n";
exit;
Blocking Bad Bots
Check this bad-bots file later for further remedial action.

There are many ways to deny access to these unwelcome bots.
Option 1:
You can check the IP address against a white list ( you add your own IP address as well as that of major search engines in this white list) and the final IP addresses can be blocked in the firewall.
Or assign the User-Agent string to a deny list which can result in 403 – status (Forbidden). It uses less server resources.
Many of the Content Management Systems (CMS) use a technique where a request for a non existent page triggers their engine to parse the request to deliver content pulled from a database. Dynamic pages would inherently utilize more server resources than static pages unless they are cached. If CMS can be made to check for the User-Agent string and send a 403 page instead of ‘preparing’ the content, it can save quite a bit of resources.
For example, one of our sites uses a CGI script in our CMS. The following snippet of code will send a 403 – Forbidden status to User-Agents wget and curl:
if ($ENV{'HTTP_USER_AGENT'}=~/wget|curl/i) {
print "status:403 Forbidden\n";
print "Content-type:text/html \n\n";
exit;
}
Option 2:
You can use .htaccess to block the bad bots assuming that you use the Apache HTTP server. In case you have a few Bad bots which use a particular User-Agent string regularly, it is easy to block them based on that string.
SetEnvIfNoCase User-Agent "^Wget" bad_user SetEnvIfNoCase User-Agent "^Riddler" bad_user Deny from env=bad_user
But it may not work out all the time. Most bad bots change their User-Agent strings often or would mimic a normal browser string. As of now few handlers of these bots keep up with the version of the browsers they try to simulate. We have seen IE version 5 or FireFox version 3.x too.
As I said earlier, this is an ongoing process to ward off bad bots. We have used different techniques on different occasions. We share a few here. If you have something better, we would like to hear about them – Please share them here in the comments.
Thank you for being with us all the way here !