Many of us have been forced to work from Home due to the Corona Virus – CoVid-19 Infection. But WFH – Work From Home is nothing new to us in TargetWoman. Personally I have set up a team to work from home almost from the beginning of TargetWoman.

The following is an excerpt from our intranet explaining – How to Optimize your Work from Home time:
- Set aside a room or create a partition in your home for the work. In other words create a ‘professional’ atmosphere and reasonable privacy for your work.
- Rig your computer, router, modem and other peripherals in the table or nearby. Use cable ties to declutter cables. Trust me – you will be in deep trouble if someone trips over the cable. Leave alone the physical damage or the trauma, your computer set up will suffer partial or permanent damage.
- Your Laptop positioning, viewing distance, viewing angle and the chair – all have a major bearing on your comfort level and productivity. Wrong positioning of the laptop will make you end up with carpel tunnel syndrome, eye strain, neck pain and back ache. Support your back by providing lumbar support. You will be working for a long time in that position – almost 9 hours a day. Set up the laptop at your eye level or about 30 degree lower. If your laptop keyboard is not convenient for long hours, get a standard wireless keyboard and a wireless mouse.
- Inform your family members, partners or other live-in members about your working schedule. They need to respect your work timings and not bug while you are working. Train your pets not to disturb you while you are at work.
- Net connectivity is vital for WFH. Get a redundant ISP just in case your main provider has a break in service. Stock up on batteries for mouse, TV remotes and other battery operated devices before you start.
- Arrange a supply of coffee and other eatables at regular intervals.
- Take a break every couple of hours.
Just because there is no one to supervise you about the actual productive time you put in everyday ( a fallacy as I explain below), you don’t waste your time on unproductive tasks.
People think there is no way their superiors can monitor the actual time spent before the computer (if your job revolves working with computers). We have tools set up in your Laptop. We would have set up the VPN in your computer along with some scripts which will run in the background – to monitor the actual time spent on each application. We know which sites you are visiting.
WFH is a privilege for both you and your company. Remember you are not working for X company or Y company – but you are working for yourself.
Now that we have covered the basics of the best accepted practices for WFH, we will explore ways to optimize your computer so that you can extract the best performance from your computer as well as be more productive than ever before.
We explore the best accepted practices for fine tuning our computers in this page.
There are tons of useful tips for computers. It would take a book to explore all the tips. For a blog, I will outline only the most important tips to enhance your productivity and ease of working.
Check the health of your Laptop Battery:
A dead laptop battery might prevent your laptop from booting in some cases. Your laptop has a Lithium Ion (Li-ion) Battery if you have purchased your laptop recently. Older laptops will have Nickel Hydride (NiMH) or Nickel Cadmium (NiCd) batteries which are heavier and have ‘memory effect’ . Li-ion batteries are lighter in weight and offer better service life than NiCd/NiMH types. But to extract the maximum life, you need to keep them between 50 – 90 % charge conditions.
All right. How do you check the battery condition?
You don’t need to download any special software for this. Your Windows 10 is quite capable of showing some very useful information about your battery. Here is how:
Type ‘cmd’ in the search box and when the pop up shows Command Prompt ,right click on it and select ‘Run as Administrator ‘ . Click Yes to proceed. And type cd \ in the command line interface. You r current path would be your C: drive now.
Type ‘powercfg /batteryreport’
It will print out a html file containing information about your laptop battery.

You can view the Battery report by selecting the file and right click to view with your favorite browser. You will find some interesting information including the battery capacity history and usage history.
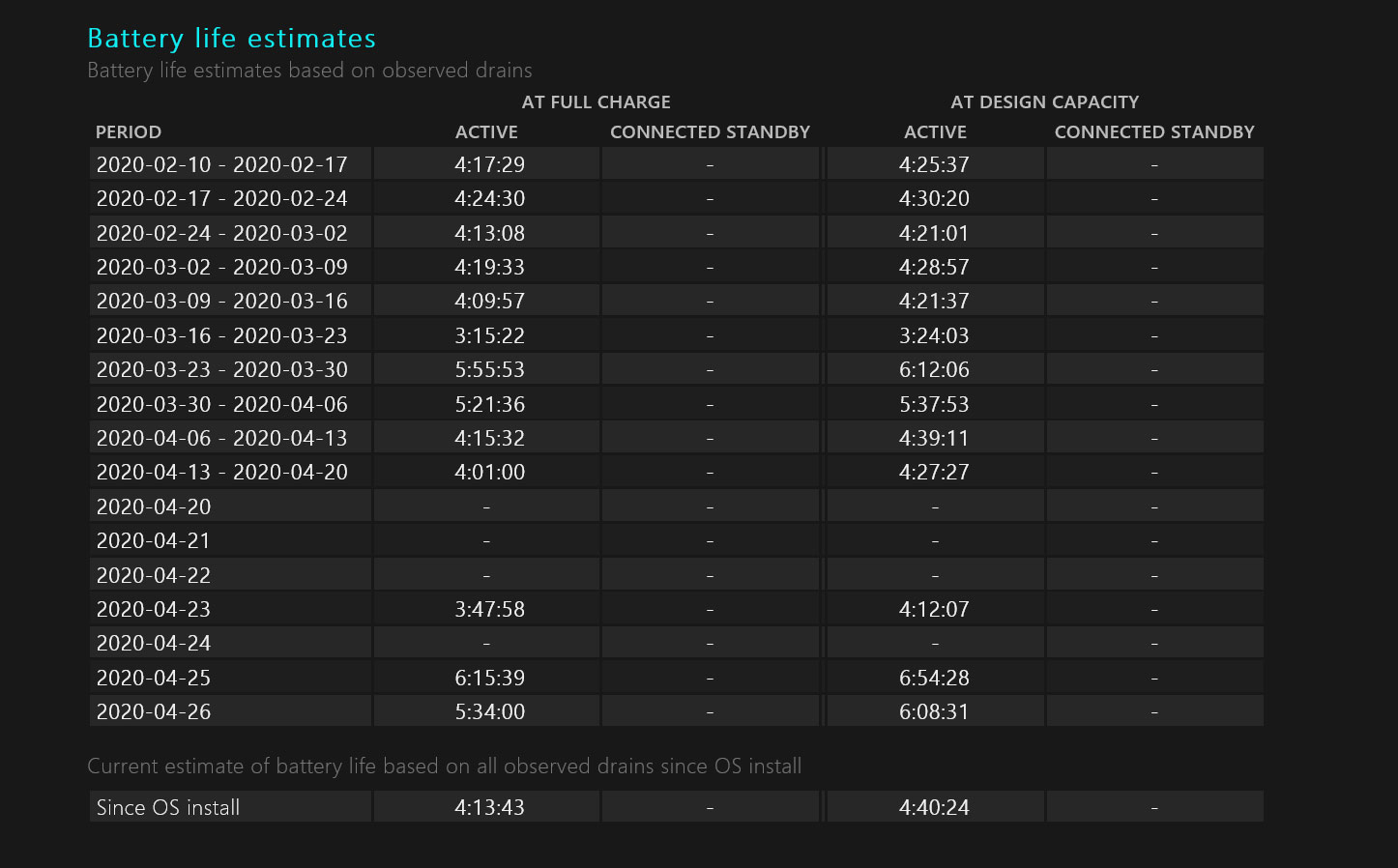
All the tips shown below assume that you have sufficient computer resources – plenty of RAM memory. Windows claims 2 GB RAM is the minimum memory required for Windows 10. The recommended memory is 4 GB for 64 bit version. But 4 GB will make your life go slow. The first thing you do to improve the performance of your computer is to increase the RAM. 8 GB is the minimum at the time of writing. I have been using computers since the time they had 48 KB RAM.
Adding an application to the right click menu :
All right. You have been hammering away at the keyboard for long. You have created many text files. You want to check them periodically. You have a nice text editor that has a low memory foot print as well as use minimal system resources – like Notapad++ or Editplus. Opening heavy weight Word Processor for checking many text files is not very efficient or productive. So how do you quickly open a text editor. When you install such editors, usually, they will set up the right click menu where you can invoke them. But many fail to do so. I will give you a quick fire technique below that will add additional application to the right click menu:
In the search box next to the Start button, type ‘regedit’ which will open the Registry Editor. If you are not sure about tinkering with your Registry which can stop the normal functioning of your computer if you make a mess, stop here.
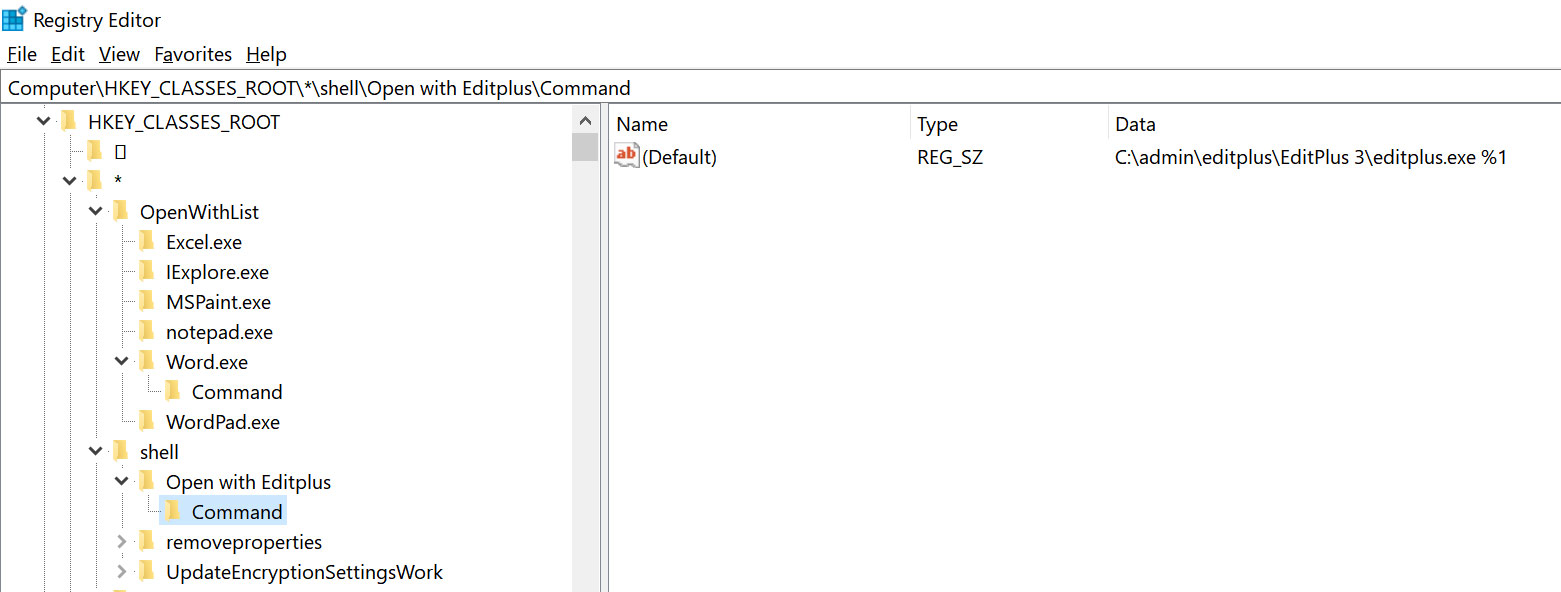
Select Computer -> HKEY_CLASSES_ROOT -> * -> shell
Right click and select New. Name this key as ‘Open With Editplus’ Or whatever your application name is. Select the key and right click. Call this sub key as ‘Command’. Select the key and on the right pane – click modify. Now copy the complete path and the application name and paste it there. In the chosen example, the editplus lives in the directory : C:\admin\editplus\Editplus3\
The application name is editplus.exe and so you fill the path and the application name along with “%1” which will invoke a new instance of the application every time you use.
Create a Virtual Desktop for better organizing your work:
If you are like many of us who have multiple Browser windows open and many applications open at the same time, the next tip – creating virtual desktops will help you to better organize your work. Trust me – once you start using these tips, you will wonder how you have been working without these for all these years.
A desktop is where you see all the open apps. You can navigate to each one of them by the shortcut – ALT and TAB keys. You can cycle through them. Windows will show what each app has in small windows. But if the app has tabs, it will show only the current active tab. Not very useful if your browser has too many open tabs. Personally I use new Window instead of tabs – precisely for this reason.
If you have extra virtual desktop, you can group one set of application in one desktop while having the second desktop for other entirely different set of applications. You can switch between them and copy and paste content between them.
Here is how you create a new desktop:
Take a look at the screen shot here. See the Blue Arrow where it points ? It points to the Timeline View or Task View.
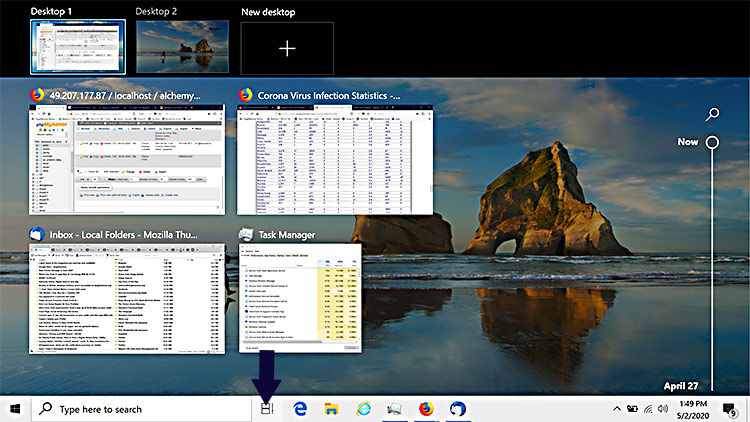 It shows the application you have been working on for the past few days in a linear fashion – hence the time line view. You can swap out the task from there and so it can also be called as Task view.
It shows the application you have been working on for the past few days in a linear fashion – hence the time line view. You can swap out the task from there and so it can also be called as Task view.
Click on that Taskview or hit Windows key and TAB key simultaneously. Click New Desktop. You will be presented with a new Desktop. Creating virtual Desktops won’t consume excessive resources. In our case it took up just about 60 MB (Desktop Windows Manager). Now you can start a new instance of your browser to any app. I noticed that Firefox browser when run in this condition, does not affect other instances of it.
You can switch between Desktops by the TaskView method or by this keyboard shortcut : Windows key and TAB key and select the appropriate desktop with the mouse. Or CTL + Windows + Right key or Left key to select the desktop you want.
Some of the options we used here can be changed here: Settings -> Sytem
I hope you use any one or all of these tips at this time of the devastating Corona pandemic.